The structured limitations of relational databases don't support modern advancements as well as NoSQL databases. The simplicity of a NoSQL key-value store offers a flexible architecture to process unstructured data and meet the sprawling data demands of even the most complex modern technologies.
Relational databases and structured data sets formed the foundation of business applications for decades before the internet was invented. Structured Query Language (SQL) further simplifies data storage and streamlines managing, processing and querying data. SQL databases can be difficult to scale up and modernize.
Not Only SQL (NoSQL) databases are more flexible systems that can process diverse data types and keep pace with the evolving generations of technology. They can process data from web apps, mobile apps, IoT, edge devices, always-on applications, AI chatbots, machine learning algorithms and large language models.
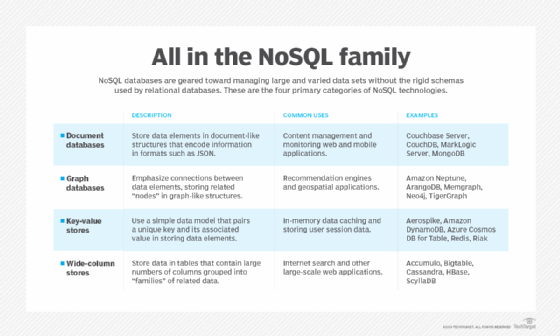
NoSQL databases have four major groups: key-value store, column-oriented, document-based and graph databases. Each of the types suit specific requirements and data types. The simplest of the four is the key-value store. It offers simple features for effective data management, excels in a variety of use cases, and delivers flexibility and scalability. But its simplicity carries potential downsides.
What is a key-value store?
The key-value store uses the key-value method and represents a collection of numerous key-value pairs. The keys are unique identifiers for different values, which can be any type of object -- a number or a string, or even another key-value pair. Values for other key-value pairs make the structure of the database more complex.
Unlike relational databases, key-value databases do not have a specified structure. Relational databases store data in tables with assigned data types for each column. Key-value databases are a collection of key-value pairs stored as individual records. Keys must be strategically named because it is the only way to retrieve the value associated with it.
Key names can be numbers, or specific descriptions of the value that is about to follow. A key-value database is like a dictionary or a directory: Dictionaries have words as keys and their meanings as values. Phonebooks have names of people as keys and their phone numbers as values. Unless you know the name of the person whose number you need, you will not be able to find the right number. Key-value stores have the same limitation.
The features of a key-value database
The key-value store is one of the least complex types of NoSQL databases, which makes the model attractive to users that need to quickly sift through large volumes of basic information. It uses very simple functions to store, get and remove data.
No query language. The database only uses keys, so it does not have a querying language. The data has no type and is determined by the requirements of the application used to process the data. You can't query anything in a key-value store, but the simplicity can boost the speed of data requests and keep latency low.
Schema-less design. Unlike relational databases, key-value stores don't have a fixed schema. They allow for flexible data representation and diverse data structures within a single database. Flexibility makes it easy to evolve data structure over time or move key-value stores from one system to another without architecture changes.
Complex data type support. Key-value stores support defined data types and more complex data objects, including semistructured data, unstructured data, arrays, images, videos, and intricate and nested data structures as values. Representing diverse data types allows for improved storage optimization, enhanced query performance and more comprehensive data modeling.
Replication, partitioning and sharding. Many key-value stores automatically support replication -- the process of storing copies of data on multiple storage nodes. They tend to support partitioning and sharding. Users have more granular control over data availability and reliability, load balancing, resource allocation and performance optimization. They can also provide backups for data in the event of a disaster.
Single tables. In relational databases, table joins can query and access data across tables by combining related data from multiple tables into a new one. The process can be inefficient and difficult to manage if values don't match up appropriately. Key-value databases don't need table joins because they store all the data in single table, which can help optimize performance and speed.
Secondary key support. One key per value can limit query options. Some key-value databases allow you to define secondary keys for values to make it easier to find information within the database. For example, a name or phone number could pull up customer data.
Use cases of key-value databases
The choice of which database an organization should use depends on its users and their needs. One of the most common uses of key-value databases is recording sessions in applications that require logins.
Session management. A key-value database can record user sessions in applications. It marks sessions with identifiers, such as a session ID number. It sorts all data recorded about each session, such as activities, clicks and actions, under the appropriate identifier. The process is an easy way to store, access and review session data that might reveal user behavior and patterns.
Caching. Key-value stores can be great for storing and retrieving temporary data. For example, a user who visits a web application might select certain preferences. The database can save and cache the data, then automatically access the data the next time the user visits, which makes for a seamless user experience. On the back end, it can reduce latency and better balance loads.
Real-time recommendations and analytics. The simplicity of key-value pairs enables the database to rapidly retrieve data, which is ideal for technologies that work best with real-time data. For example, key-value databases can help collect sensor data from IoT devices and update inventory systems in real time. They can personalize website advertising with unique offers and recommendations for users based on cached user behavior data and real-time site interactions.
Queueing. Key-value stores can help queueing systems to keep data organized by recording queue values, such as time of day and date, queued items and queue names. Queue data can help execute tasks in the correct order.
Metadata storage. Key-value databases can store a variety of other data and metadata, including data related to configuration settings, user profiles, products, images, audio and videos. They can provide higher levels of data access, scale throughput and improve raw performance.
The role that key-value databases serve in the e-commerce vertical is one practical example of their function. On an e-commerce website, a key-value database can record data pertaining to an individual shopping session. The data can include when the user logged in and out, what terms they searched for, what categories and items they clicked on to view, and what items they added to or removed from their cart. By recording the user's behavior, the database can automatically tailor banner ads and product recommendations to the individual. When the user checks out, the database can access cached preferences, such as the credit card the user saved for default purchases, streamlining the experience.
Relational databases are generally better to use with payment transaction records. Session records prior to payment are better off in a key-value store because more people tend to fill their shopping carts and subsequently change their mind about buying the selected items than people who proceed to payment.
A key-value store is quick to record and retrieve data simultaneously. Its built-in redundancy ensures no item from a cart gets lost. The scalability of key-value stores helps in peak seasons around holidays or during sales and special promotions because of the sharp increase in sales and an even greater increase in traffic on the website. The scalability of the key-value store ensures the increased load on the database does not result in performance issues.
Advantages of key-value databases
Different database types exist to serve different purposes, which can make choosing the type of database to use obvious. The simplicity of a key-value database is one of several advantages it offers to users:
Simplicity. The straightforward commands and absence of data types can make work easier for programmers. Data can assume any type or even multiple types when needed. The key-value store is one of the least complex NoSQL databases, which makes the model attractive. It uses simple functions to store, access and remove data.
Speed. Given their simplicity, key-value databases are usually quick to respond, provided they are in a well-built and optimized environment. They also make it easy to sort keys systematically, such as alphabetically, numerically, chronologically, by file type and data size. Systematic organization makes it easier to find desired data quickly.
Scalability. Unlike relational databases, which only scale vertically, key-value stores are also infinitely scalable horizontally. They can handle large volumes of data at scale and across distributed systems, which can support growth and flux over time.
Flexibility and mobility. The absence of a query language and strict data schema means the database can move between different systems without having to change the architecture. Its flexibility makes it easier to store a variety of data types and evolve the data structure as needs and technologies change.
Reliability and stability. Key-value databases with built-in redundancy can cover for a lost storage node, enabling duplicated data to replace lost data. The ability to distribute data across nodes and balance loads can help ensure optimal performance and data availability. Data distribution can translate to superior reliability and stability, which is especially important in today's always-online landscape.
Disadvantages of key-value databases
Depending on the situation, key-value stores' best asset can be a weakness. A lack of complexity limits the options for organizations with more complex data needs:
Depending on the situation, key-value stores' best asset can be a weakness.
Simplicity. Key-value stores lack refinement. Some users can feel limited with no language or straightforward means to query the database with anything else other than the key.
No query language. Without a unified query language to use, queries from one database might not transfer into a different key-value database. If you lose a key, you have no way of identifying its associated value. Secondary keys help cover the potential issue.
No filtering of values. The database sees values as blobs. It can't make much sense of what they contain. It returns whole values on request rather than a specific piece of information. Updating data requires updating the whole value.
Analytics limitations. Key-value databases can improve real-time data storage and access, but their specific querying capabilities can limit analytics functions. They can typically support simpler analytics functions, but more complex analytics might require a database that can retrieve data based on a variety of queries.
Data inconsistency. The lack of standardization can lead to poor data quality, consistency and integrity when storing unstructured data. The potential tradeoff for more data availability is lower data accuracy, which can affect decision-making.
Popular key-value databases
There are several key-value store options to consider. Examples of top-rated options from reputable sources including G2, Gartner and Capterra include the following:
Aerospike. The real-time platform facilitates billions of transactions. It can help reduce server footprint and enable high performance of real-time applications.
Couchbase. This NoSQL database can function as a key-value store and a document-oriented database. Its primary design supports personalized customer and employee experiences.
DataStax. DataStax Astra DB is a key-value database built on the open source Apache Cassandra project. It supports a variety of AI tools, including generative AI applications.
Redis. Redis is an open source key-value database. Redis is known as a data structure server and has keys containing lists, hashes, strings and sets.
Carefully assess your requirements and the purpose of your data before you select a database. Given the rapidly evolving technology landscape, it's critical to ensure your database allows you to make the most of your data without compromising performance.
Jacob Roundy is a freelance writer and editor with more than a decade of experience with specializing in a variety of technology topics, such as data centers, business intelligence, AI/ML, climate change and sustainability. His writing focuses on demystifying tech, tracking trends in the industry, and providing practical guidance to IT leaders and administrators.
Alex Williams is an independent IT consultant and owner of Hosting Data UK. He has na decade of experience as a developer and is knowledgeable in IT systems, cybersecurity, data management, internet privacy and finance.