What is denormalization and how does it work?
What is denormalization?
Denormalization is the process of adding precomputed redundant data to an otherwise normalized relational database to improve read performance. With denormalization, the database administrator selectively adds back specific instances of redundant data after the data structure has been normalized. A denormalized database should not be confused with a database that has never been normalized.
Normalization vs. denormalization
Denormalization helps to address a fundamental fact in databases: slow read and join operations.
In a fully normalized database, each piece of data is stored only once, generally in separate tables, with a relation to one another. To become usable, the information must be queried and read out from the individual tables, and then joined together to provide the query response. If this process involves large amounts of data or needs to be done many times a second, it can quickly overwhelm the database hardware, reduce its performance, and even cause it to crash.
Real-world analogy
Imagine a fruit seller has two daily lists: one of in-stock fruit and another with the market prices of all fruits and vegetables. In a normalized database, these lists would be two separate tables. If a customer wanted to know an item's price, the seller would check both lists to determine if it is in stock and at what price. The process would be slow and annoy the customer.
As an alternative, the seller creates another list every morning with just the in-stock items and the daily price of each item. Combining the two lists provides a single reference that can be used to quickly generate answers. This is a type of database denormalization.
Important considerations and tradeoffs for data denormalization
For normalizing data, one important consideration is if the data will be "read heavy" or "write heavy." In a denormalized database, data is duplicated. So, every time data needs to be added or modified, several tables will need to be changed. This results in slower write operations. Therefore, the fundamental tradeoff is fast writes and slow reads with normalization versus slow writes and fast reads with denormalization.
Real-world analogy
Consider a database containing customer orders from an e-commerce website. If many orders come in every second but each order is only read out a few times during order processing, prioritizing write performance might be more important. In this case, a normalized database would be preferable.
However, if each order is read out multiple times per second to say, provide recommendations to the customer or by some big data trending system, then faster read performance is more important. In this case, a denormalized database would be the better option.
Another important consideration in a denormalized system is data consistency. In a normalized database, each piece of data is stored in one place so the data is always consistent. In a denormalized database, data might be duplicated so it is possible that one piece of data is updated while another duplicated location is not, resulting in a data inconsistency called an update anomaly. The risk of update anomalies places extra responsibility on the application or database system to maintain the data and handle these errors.
When should you denormalize a database?
In a normalized relational database, multiple separate tables are maintained to minimize the amount of redundant data. Simply put, normalizing involves removing redundancy so only a single copy of each piece of information exists in the database.
Also, when a database uses normalization in SQL, it stores different but related types of data in separate logical tables called relations. When a query combines data from multiple tables into a single result table, it is called a join. The performance of such a join in the face of complex queries is often below par and/or costly.
To avoid these issues, database administrators explore the alternative: denormalization, in which redundant data is deliberately added to a normalized schema. Denormalizing a database requires that its data has first been normalized. In other words, denormalization does not mean reversing or avoiding normalization, but optimizing the database by adding redundant data to improve its efficiency and query performance.
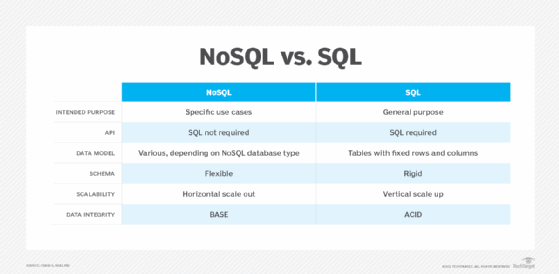
Database denormalization: Going beyond relational databases and SQL
Examples of denormalization go beyond relational and SQL. Applications based on NoSQL databases often employ this technique, particularly document-oriented NoSQL databases. Such databases often underlie content management systems for web profile pages that benefit from read optimizations. Here, denormalization reduces the amount of time needed to assemble pages that use data from different sources. In such cases, maintaining data consistency is the job of the application and application developer.
Columnar databases such as Apache Cassandra also benefit from denormalized views, as they can use high compression to offset higher disk usage and are designed for high read access.
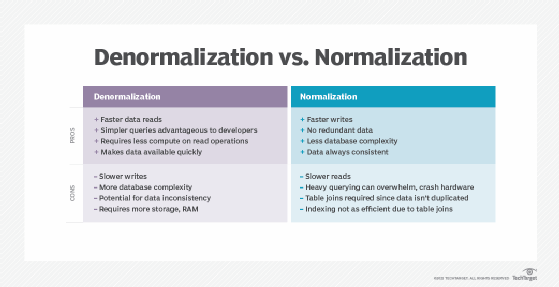
Denormalization pros and cons
Denormalization on databases has both pros and cons:
Pros
- Faster reads for denormalized data.
- Simpler queries for application developers.
- Less compute on read operations.
Cons
- Slower write operations.
- Increases database complexity.
- Potential for data inconsistency.
- Additional storage required for redundant tables.
Advancing technology is addressing many of the above cons. Also, the falling costs of disk and RAM storage have reduced the cost impact of storing redundant data in denormalized databases. Additionally, increasing emphasis on improving read performance has necessitated the use of denormalization in many databases. For all these reasons, denormalization is now a common approach in database design.
Denormalization in logical design
The specifics of the automated denormalization system in a database vary between database management system (DBMS) vendors. Because denormalization is complicated, automated denormalized views are generally only a feature of a paid DBMS. Some DBMSes provide materialized or indexed views, which refer to special views or summaries in which data is stored on disk, i.e., materialized to improve query execution times and reduce execution costs. Two examples of such DBMSes are Microsoft SQL Server, which uses indexed views for denormalized data, and Oracle databases, which also use precomputed tables or materialized views. Both use cost-based analyzers to determine if a prebuilt view is needed.
Database administrators can perform a denormalization as a built-in function of a DBMS or introduce it as part of the overall database design. If implemented as a DBMS feature, the database will handle the denormalization and ensure data consistency. If a custom implementation is used, the database administrator and application programs are responsible for data consistency. To add denormalized tables as part of the database architecture design, some DBMSes like MySQL use a create view statement.
Denormalization in data warehousing
Denormalization plays an important role in relational data warehouses. Because data warehouses contain massive amounts of data and can host many concurrent connections, optimizing read performance and minimizing expensive join operations is important. Denormalization helps data warehouse administrators ensure more predictable read performance for the warehouse.
This is particularly true in dimensional databases as prescribed by influential data warehouse architect and author Ralph Kimball. Kimball's emphasis on dimensional structures that use denormalization is intended to speed query execution, which can be especially important in data warehouses used for business intelligence.
Choosing which database management system depends on an organization's needs. Check out the differences among SQL, NoSQL and NewSQL and how to select the right database system. Also, learn how to modernize a data warehouse for real-time decisions.






